Overview
Valence is a middleware engine that lives inside your Salesforce org and moves data between your org and other external systems and services.
You configure it inside Salesforce’s user interface (works in both Classic and Lightning), and moving the configuration Metadata Files between different Salesforce environments is simple and straightforward. That means you can build and test Valence in a sandbox, and easily promote the entire configuration (or parts of it) to your production org. You can also export these configuration files from your org to keep backups.
Valence was built to handle large data volumes; people move millions of rows of data in and out of Salesforce with it.
Integrations are a complex space, so Valence contains many layers of error handling and diagnostics to help you navigate what is happening with your data movement.
Every integration has its own little wrinkles and intricacies, so we’ve focused on a balance between features and capacities that every integration wants, and hooks for extensibility throughout the engine when special adaptation is required. Regardless of what extensions you add to your setup, Valence is designed for admins to always be able to declaratively design what data moves, where, when, and how. The way extensions hook into the engine allows them to be configured and used within the normal Valence user interface screens.
Valence is the distillation of many years of experience working with integrations on the Salesforce platform, and is tuned to understand the nuances of the platform better than any other integration product. That means you can do things like deliver parent and child records out of order, populate Master-Detail fields based on external identifiers, and upsert on formula fields.
Let’s dive in and break down how record movement works using Valence.
How Does Data Move?
The basic building block in Valence is something called a Link, which you can think of as a pipe that sits between Salesforce and an external system. Data flows into one end of the pipe and out the other end.
More specifically, a Link represents a connection between an object in Salesforce and a table/object somewhere else. For example, you might have the Company table in your ERP connected to the Account object in Salesforce. That would be a single Link. If you connected the Person table from this fictitious ERP to the Contact object in Salesforce that would be a second Link.
A Link is a container for many additional components that are working together to move data from A to B, and has its own mappings, schedule, settings, configurations and analytics.
If we were to look inside a Link “pipe” you’d see that it looks something like this:
Source Adapter
Filter A
Filter B
Filter C
Filter …
Target Adapter
Adapters
An Adapter knows how to work with a system or data store. Analogy: an Adapter is like a translator; if an Adapter can speak Latin then Valence can work with that Adapter to change English to Latin and vice-versa.
Every Link defines two Adapters that it will use: a source Adapter to get data from, and a target Adapter to send data to. Some Adapters can only be used as a source (read from a system but not write to it), some only as a target (write to a system but not read from it), and some can be either.
Example Adapter Use Cases
An Adapter that can talk to Quickbooks (or SAP, or Netsuite, or any number of business applications and services)
An Adapter that can talk to back-office databases your IT team manages
An Adapter that can talk to a second Salesforce org
An Adapter that can speak GraphQL
An Adapter that can speak REST or SOAP
Filters
A Filter processes a data record as it moves through the Valence engine. It is an opportunity to observe and possibly manipulate records as they go by. Any number of Filters can be attached to a Link, and the order in which they fire (and any configuration of them) is controlled by the admin setting up the Link.
Example Filter Use Cases
Adding a constant value to records going by
Manipulating date/time strings to be friendly to the target system
Filtering out records that should be ignored and not processed
Validating records for custom business logic that would add a warning or an error to a record
Transforming record shape or field values
Getting More Adapters and Filters
Valence comes with certain Adapters and Filters out of the box. You can get more from:
Read our documentation on Creating An Adapter or Creating A Filter
Custom-built for you by Salesforce implementation partners with Valence expertise
Prebuilt from businesses that write Valence extensions as a product offering
We’re happy to answer questions about what Adapters and Filters exist and where to find them if you write to our team at success@valence.app.
When Does Data Move?
At this point we understand that a Link is a like a pipe that moves record data from one system to another, and we have a sense of what elements participate in that movement. But when do records move?
Valence supports both scheduled and real-time data movement, inbound to Salesforce or outbound from Salesforce. Whether a Link is scheduled, real-time, or on-demand will depend on what trigger conditions you configure for it. It can even be a mix of all three!
There are a large variety of trigger conditions that will cause a Link “run” (some records moving from A to B).
The Link is on a schedule and it’s time to run again
The Link is configured to run after another Link, and that other Link just finished a run
The Link was invoked by an Apex Trigger that fired
The Link was invoked as part of a Salesforce Process or Flow
Fresh data was delivered from an external system
An admin clicked the “Run Now” button
An admin uploaded a CSV file with new records
The Link was invoked programmatically
A Link Split uses this Link as a secondary delivery target and the primary Link just finished
What Happened During Movement?
Some of the big questions with any integration are: what happened? How did it go?
Valence is very good at answering these kinds of questions.
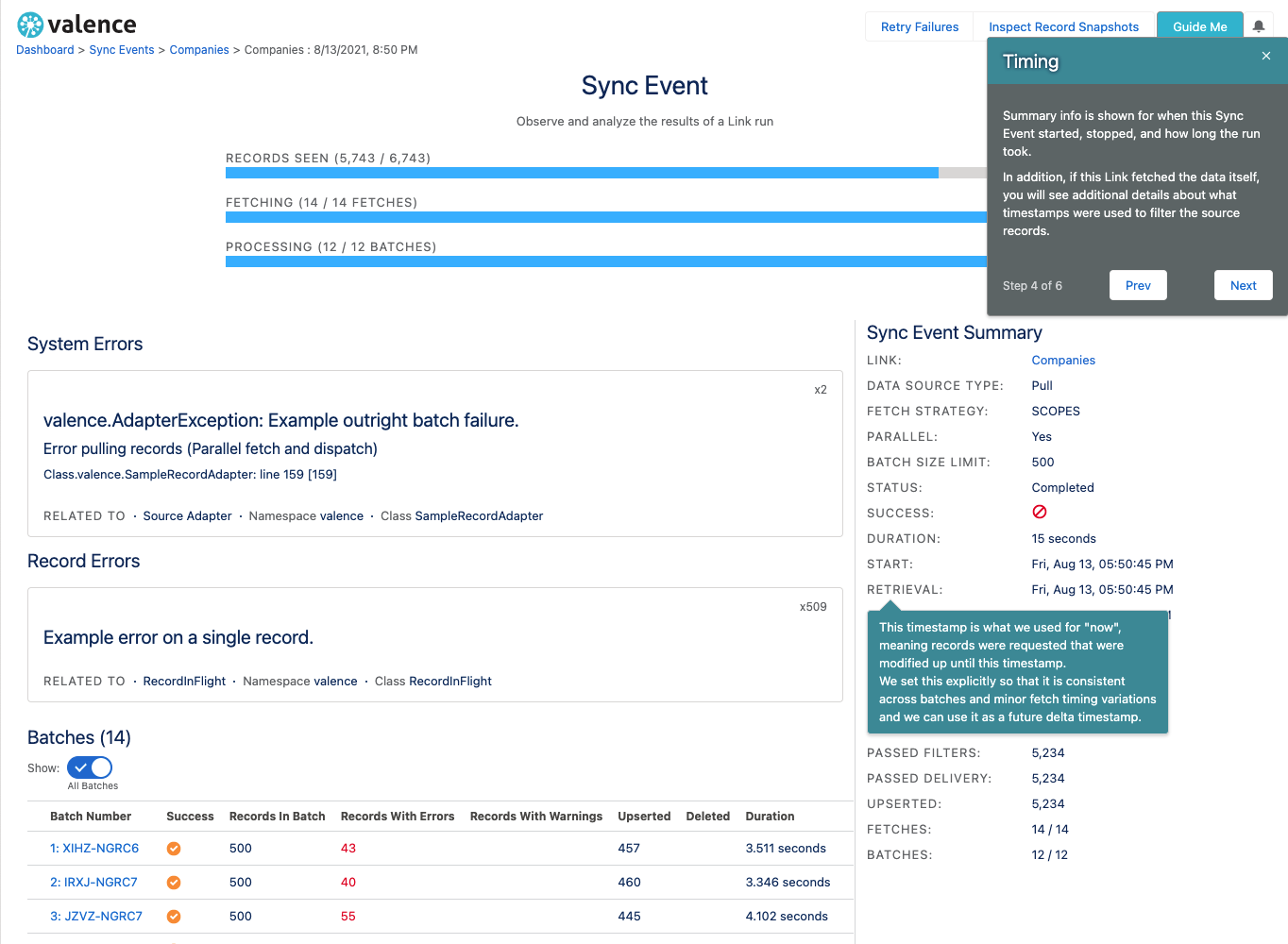
Whenever a Link runs, an SObject record called a Sync Event is generated. This record holds all kinds of information about what happened during the run, like:
How many records did we expect to move?
How many records did we move?
How many records had errors? warnings?
How many records were ignored?
How many records were successfully delivered?
What errors occurred and which records had those errors?
How long did this take?
Which fields did we see? What were their population percentages?
And many more
Tip
Since a Sync Event is an SObject, you can use normal Salesforce features to report on it, put it in a dashboard, an email, or anything else you’d like to do in order to review movement or be notified when certain things happen.
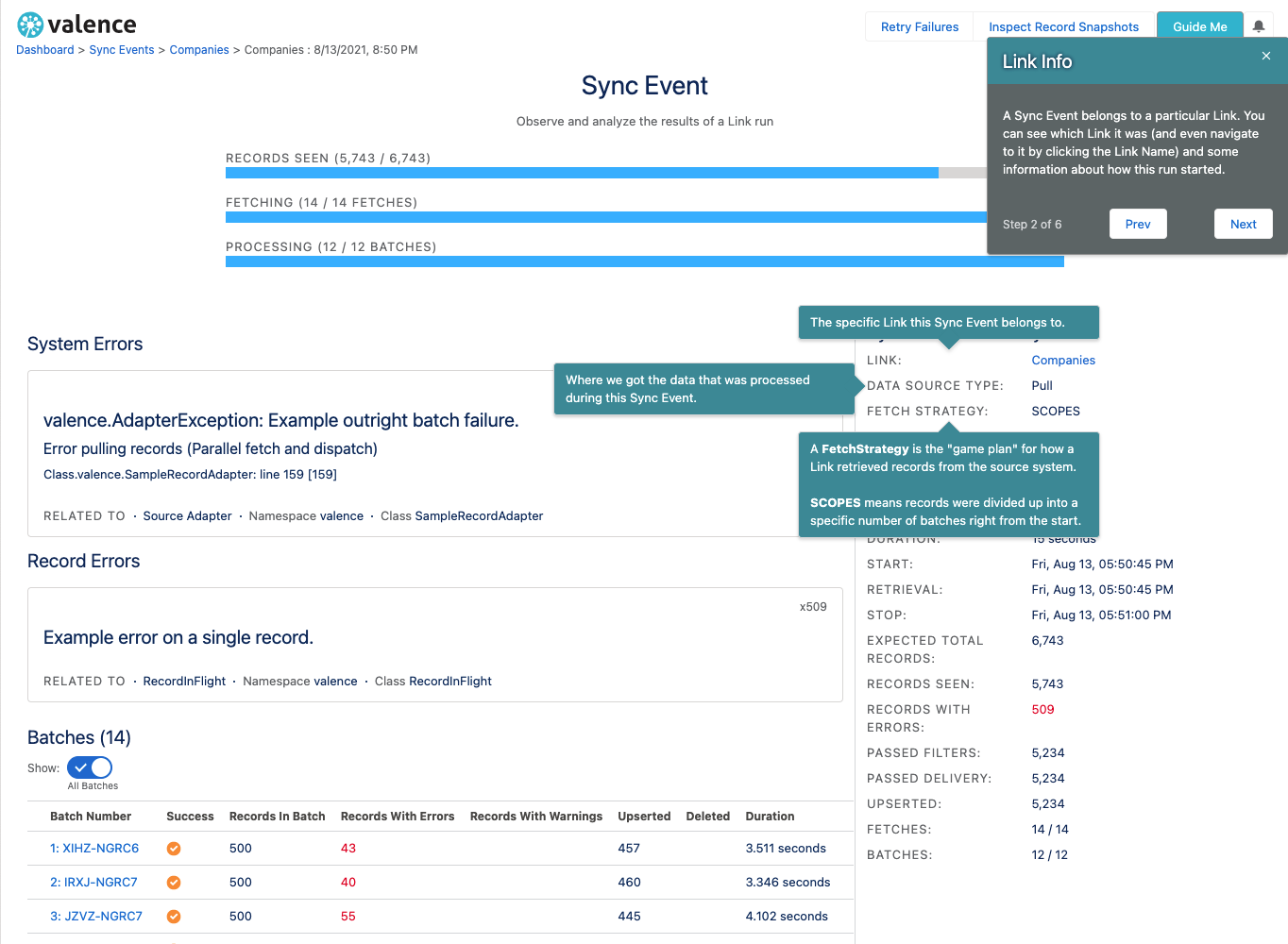
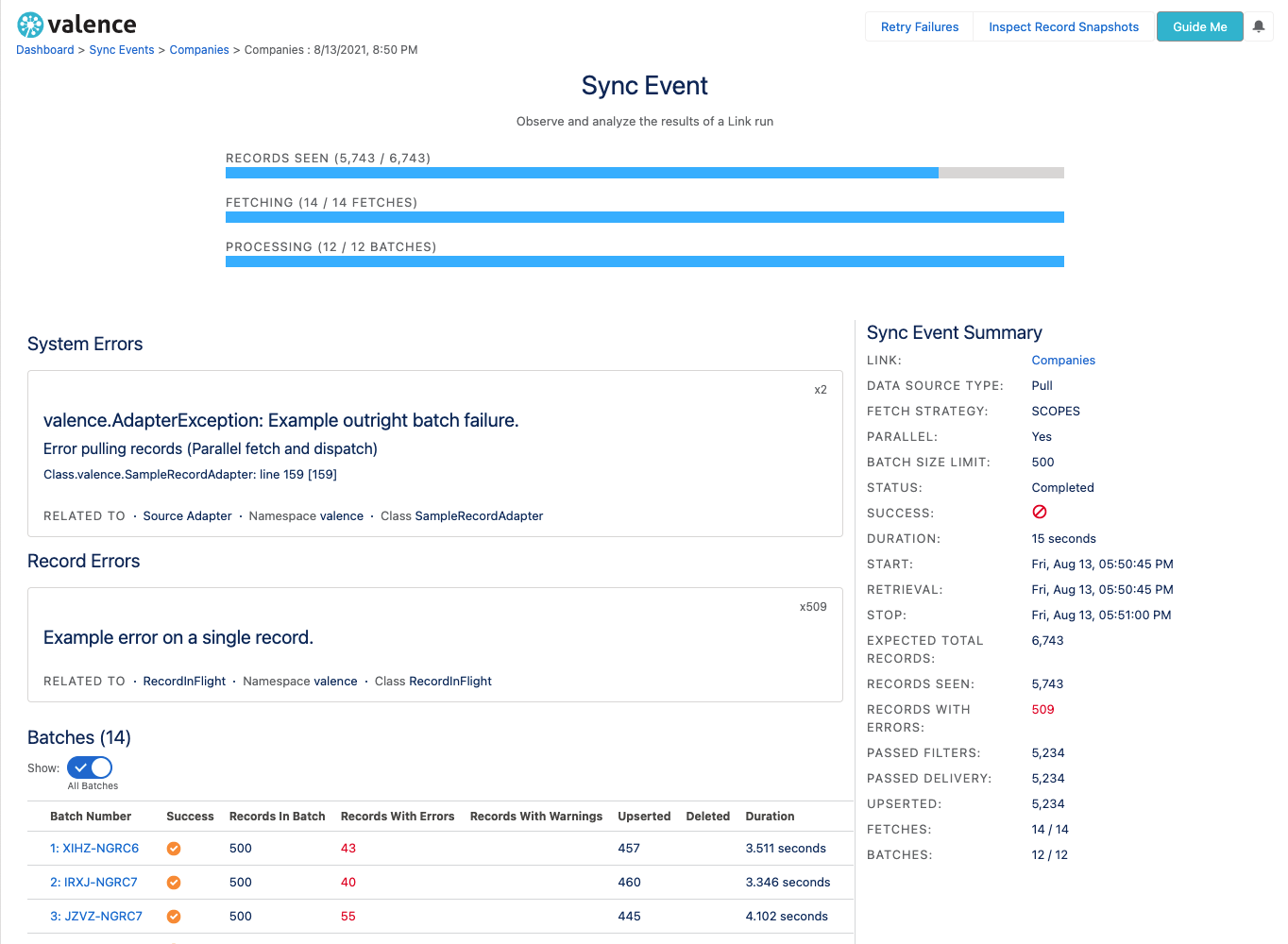
In the Valence user interface, you can see this information by looking at the Sync Event Summary screen. This screen will give you a live, real-time picture of the run as it is happening and summary information afterwards.
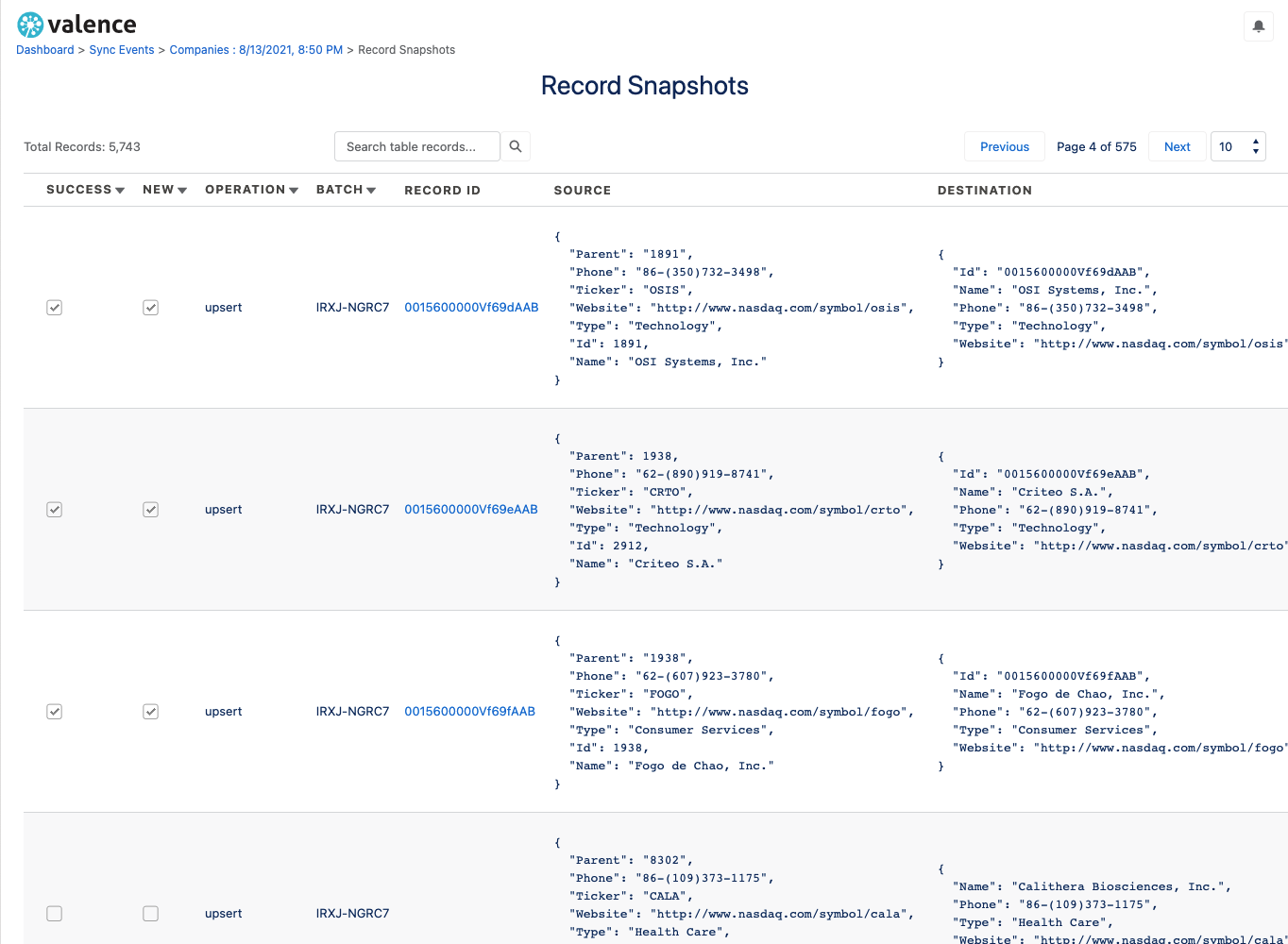
In addition to metadata about the run itself, you can also inspect individual records in their before and after states to understand how they were transformed and why you are seeing certain error messages.
Salesforce Limits (or Lack Thereof)
Anyone working with Salesforce knows that every automated process on the platform has to operate within the governor limits defined by Salesforce. These limits can be quite restrictive, so how can a platform-native middleware engine move millions of records without running into trouble?
Valence was designed and built from the ground up to be highly-parallel and operate across many different execution contexts as needed. In other words, that’s like having a magic lamp and your third wish is always to ask for three more wishes. This load balancing is done internally by the engine and typically you won’t have to think about it or know about it.
Here’s an example: the maximum number of records that can be written to the Salesforce database in a single execution context is 10,000. So what happens if an external system hands Valence 15,000 rows in one fell swoop?
All 15,000 records will be written to the database by Valence. Valence will detect that it has too many records for a single write, and it will split the records into batches across different execution contexts so that no limits are exceeded.
From the perspective of both the admin user and extension developers, Valence abstracts away the Salesforce governor limits so you don’t have to think about them when designing your data flows with Valence.
Getting Help Inside the Application
There is a comprehensive built-in help system inside of the Valence user interface that will help you understand each screen and what you can do there.
Look for the Guide Me button on the top right.

It will open an overlay that you can flip through to see different cards and popups explaining facets of what you are seeing on the screen.