Handling Errors
Overview
All integrations fail at some point. It’s not possible to have so many moving parts and interconnected systems and not have something go awry.
What’s important is how we handle it.
Here’s our philosophy when it comes to integration error handling:
At a bare minimum we should know that something went wrong.
Beyond knowing something is wrong, it would be nice to have a sense of what specifically went wrong, and perhaps why, and some clues towards a resolution (the more detail the better).
Beyond knowing the details of the failure, it would be good if the system could recover on its own (if possible).
If it can’t recover on its own, then there should be a way that we can help it recover manually.
These principles are reflected in the error handling and recovery designs within Valence, which are battle-tested and quite resilient.
Types of Errors
Let’s define a few different patterns of errors that can occur so we can talk about what each means and how to deal with them.
Errors are captured by Valence and shown on the Sync Event Summary screen in realtime while the Link is running, and also afterwards.
System Error
This kind of error happens at a very fundamental part of a Link run. Maybe the other external server is offline, or we have the wrong authentication info, etc.
System errors stop the Link run. Things are too broken to continue (or sometimes, to even start).
Batch Error
Valence is highly-parallel and splits the work into a number of batches, each in its own execution context. A batch error fails an entire batch, but the overall Link run continues.
Maybe when Valence goes to fetch a particular page of results one of those results is malformed and that page throws an HTTP 400 error (saw that one just recently). Batch errors show at the top of the Sync Event Summary screen and also within each batch.
Record Error
A single record has an error that is blocking its individual success (and consequently the success of the overall job). The most common cause of these are things like a record has a blank field that is required in the other system, or its value is too long, or fails validation in some way. Every database has some bad data and you’ll find yours with Valence.
This record will not succeed but its siblings in the batch might, and certainly other batches will succeed or fail regardless of this record’s plight.
When a record error occurs Valence will take a snapshot of the state of that record before and after transformations, and you will be able to browse and look at field values for all failing records. This is one of our most powerful features and is hugely beneficial in diagnosing issues.
Honorable Mention: Record Warning
Not technically an error but worth mentioning here, a warning is applied to a record but does not block its success. This is a way to flag things for attention that aren’t worth failing a run over.
Honorable Mention: Ignore Reason
Separate from a warning, a record can be marked as ignored by any Adapter or Filter. This is commonly used to filter or refuse records that you are receiving but know you don’t want to pass along to the target system. When records are marked in this way the Adapter or Filter that did so is required to provide a reason, and that reason is shown on the SyncEventSummary screen.
Error Durability
In addition to types of errors, we’re also going to separate errors into two categories based on duration:
Ephemeral - short-lived, likely to go away if circumstances were a little bit different
Durable - long-lived, something intrinsic to the data or the configuration
An ephemeral error is something like an external server being temporarily unavailable, but if we tried it again in a couple minutes or a couple hours it would work. (One of our customers has an API that seems to take a nap every night at midnight for a little bit, so their hourly run fails exactly once a day.) Another example would be some kind of record locking contention because of parallel writing.
A durable error is typically based on the data itself, or how the Link is configured. If we have the wrong authentication details, trying again in an hour isn’t going to make that go away. If we have a record with a malformed email address, we can’t keep jamming it into Salesforce hoping it will be accepted.
Valence Error Handling
Now that we’ve laid out ways of categorizing and labeling errors, let’s walk through what features exist in Valence to help us mitigate or resolve these errors.
Last Successful Sync
If you’ve read our explanation of Delta Sync, then you’re already familiar with this concept. This is your main line of defense against integration errors. If a run fails, the same records (plus possibly some additional data) will be tried again on the next run.
Let’s talk about how this helps us with our types of errors:
- Durations
Ephemeral - great; we’ll be trying the same data again on the next run
Durable - good; can’t resolve durable errors by itself, but if you fix the problem (repair a record, change the auth credentials, etc) the next run will take advantage of your work so you can just correct and sit back, no further work needed.
- Types
System Error - great; since we end up with a fresh run, these are discarded (of course the new run might throw more)
Batch Error - great; same as above
Record Error - great; same as above
- Modes
Pull/Fetch - Supported
Push/Realtime - Not Supported
Note
Be aware that Last Successful Sync only applies to Links that are pulling data from somewhere (like a scheduled Link fetching invoices hourly from Quickbooks). We can tell that source Adapter “Hey, give me those same 1000 records again please”. If our Link is being fed data in realtime (such as from an Apex trigger or from an external system sending records into Valence via the Apex REST API), then we have no way to go back to the well to get records again. We’ll talk about this scenario more in Retry Failures.
Automated Replay
There is a feature in the Settings screen for a Link that can be toggled on and off (default: off), and you can also configure a maximum number of attempts.
Automated replays exist for those scenarios that are very ephemeral, where a record is failing but the same exact record just seconds or minutes later would not have an error. We added this feature to help people with highly-concurrent inbound to Salesforce record flow, especially with realtime pushes coming in from external systems via the Apex REST API.
If you have automated replays turned on and some records in a run fail, just those records are immediately processed in a new Link run, and that run will attempt itself repeatedly until either it hits the attempts limit or all records are successful. Replay Sync Events will have a banner like this:

- Durations
Ephemeral - great; designed for very short duration ephemeral errors
Durable - N/A
- Types
System Error - N/A (only re-processes failed records)
Batch Error - N/A (only re-processes failed records)
Record Error - great; designed to fix record-level errors, will grab individual failing records and keep trying them again (and if some succeed it will only keep retrying the failures)
- Modes
Pull/Fetch - Supported
Push/Realtime - Supported
Retry Failures
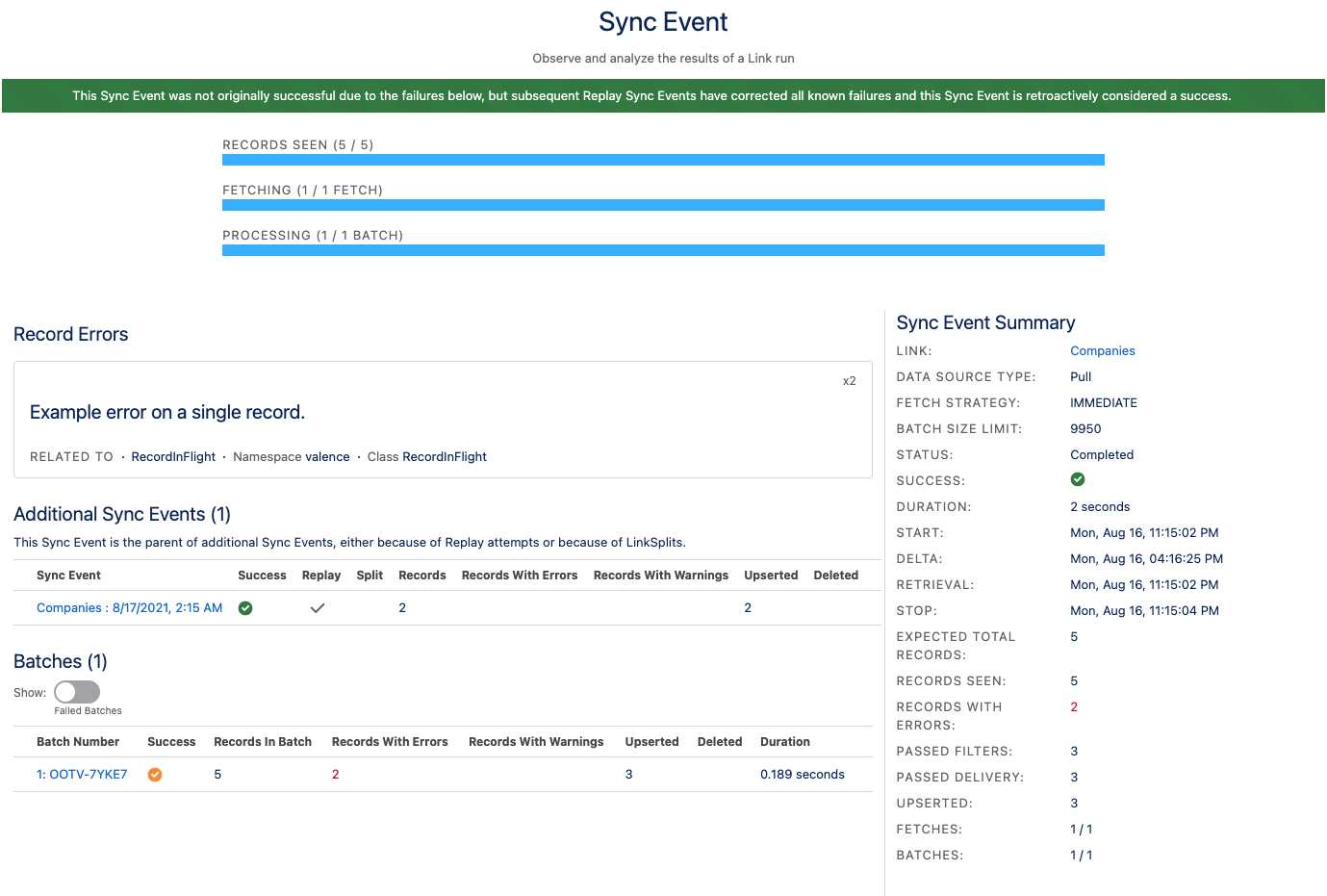
Retry failures is an operation you can trigger manually from the Sync Event Summary screen after a Link run is over if it had errors of any kind. This starts a new Link run with some unique behavior.
Any batches that threw errors and failed outright (no records even received for that batch) will be retried (fully successful batches will not be retried)
Any individual failing records whose batch finished (didn’t explode) will also be retried (we call these “loose failing records” since they are gathered up from all the batches).
This is a very powerful tool. Let’s say you have a big run that pulls in three million records, but 15 batches timed out during the fetch, and you also had a validation rule you forgot about block about 70,000 records of the 3,000,000. You go in and fix the validation rule and you’re ready to get your missing records. Since the run overall was a failure you could use last successful sync to pull everything again, but that’s a lot of records you already successfully received.
So, instead of doing another normal run you click “Retry Failures”. A new Link run starts with, say, 30 batches. That’s the 15 failing batches, plus enough batches to put all the loose failing records into batches of their own for reprocessing. Way fewer records, so this run is done really quickly. We fixed the validation rule so those 70,000 records came in successfully, and out of our 15 bad batches 11 of them were successful. But…uh oh…four batches timed out again! Shoot.
What do we do? Click Retry Failures on this replay Sync Event, of course! You can chain retries as many times as you need to.
This third run (2nd retry) is even faster because it’s just four batches, and thankfully all four come through and we’ve finished our three million record run. Congrats!
All of the replay runs will link up to the original failing Sync Event, and likewise that original Sync Event will list the child replay attempts on its Sync Event Summary screen.
And, if we are eventually fully successful through our replay attempts, the original Sync Event is changed from a failure to a success!
- Durations
Ephemeral - N/A - use one of the other strategies
Durable - great; since it will not run until you tell it to, and you can try it as many times as you want while you iterate through your fixes and troubleshooting
- Types
System Error - N/A (only re-processes failed batches and failed records)
Batch Error - great; will retry any batches that failed in the previous run
Record Error - great; will cherry-pick failing records from each batch of previous run and reprocess them in the new run
- Modes
Pull/Fetch - Supported (see additional node)
Push/Realtime - Supported
A few extra things to be aware of:
If you set a Link’s “logging level” in the Settings screen to “None”, you will not be able to retry individual records since no snapshot of them would have been saved. Set to any level other than “None” to capture failing records.
This is the only mechanism where you can retry records that were pushed in via a realtime data source. That’s because Valence captures a record “snapshot” and serializes it, so if we need to reprocess that record we have a copy to work with and don’t need to go back to the source.
With the high value from the previous point comes a warning: once a snapshot has been captured it’s going to start going stale. If you retry a record you are always running the risk that you will overwrite good data if that record has been updated in the time from the original failure and when you click retry. Typically this is not an issue but just take a minute before you click Retry Failures and think about how or if these records might have already come through again successfully.