Schema
What Does a Schema Look Like?
Schemata are formal descriptions of the data modeling of records. We also sometimes refer to this as the record’s “shape”. They answer questions like:
What entities are available to read from? To write to?
What fields exist on those entities?
What’s the data type of each field? Restrictions on it? (character length, required, etc)
What are the relationships to other entities? What is their cardinality? (One to Many, One to One, etc)
Valence has a sophisticated and nuanced understanding of schemata. It’s a integral part of the engine, since the primary purpose of any middleware is to translate data from one schema to another!
Table Schema
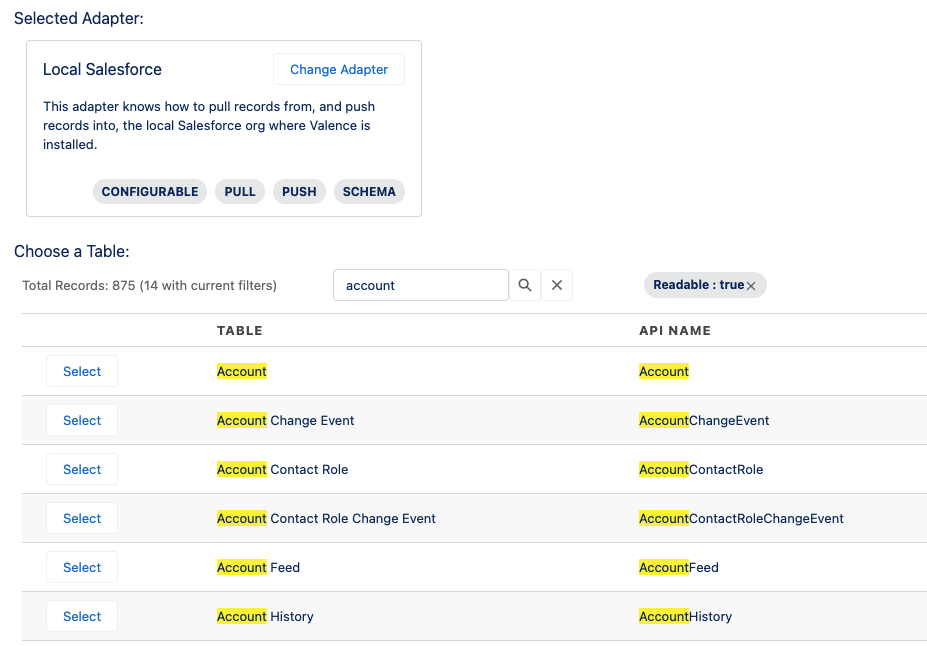
When you are setting up a Link you are presented with your options for which table (a.k.a. entity, object) to interact with. This is a dynamic investigation by Valence and will reflect any changes in the schema that have occurred (for example, a new custom object being added to your Salesforce org). You can search and filter to help narrow your selection. Also, this screen is context-aware; for example, when selecting a target table, any tables that came back as not-writeable won’t be shown.
Field Schema
Each record has two schemata: what it looks like in the data source system, and what it should look like in the target system. Valence provides a schema browser as part of configuring a Link that will allow you inspect and develop an understanding of these record shapes.
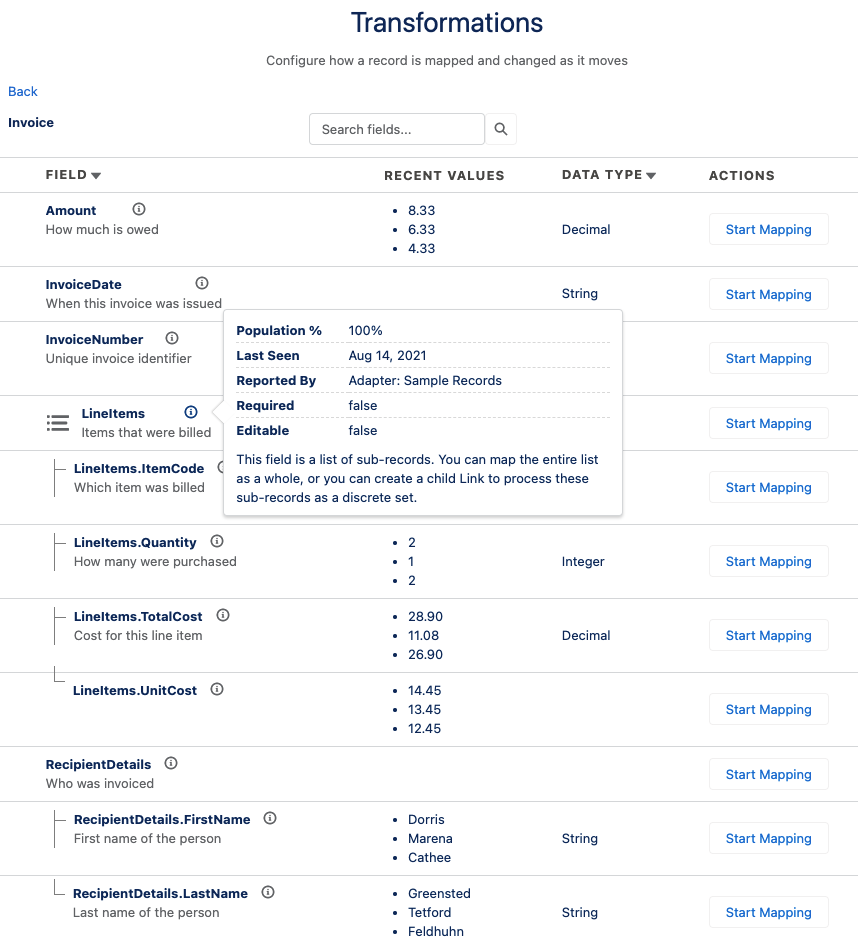
As you build up mappings and transformations, Valence will also show you a representation of your record as it is currently being used (only showing which fields are being read, or written to, etc) so you can have a really crisp understanding of what you’re actually working with.
Where Does the Schema Come From?
The schema you see in the schema browser is actually built up from many layers of information that Valence can access that each provide clues about record shape. What you see is the distillation of all of these layers into what the record truly looks like, and why.
We do this because APIs can be unreliable when describing what their entities look like. Maybe it says it will send you seven fields but actually it sends nine. If all we did was trust the API’s declaration, you’d never be aware of (least of all, use) those extra fields.
1. Adapters
Adapters can share information about their schema by implementing the SchemaAdapter interface, which allows Valence to ask the Adapter about tables and fields in a system that Adapter talks to.
An Adapter’s schema may vary depending on the specific external endpoint a Link is interacting with. If you were using the Remote Salesforce Adapter to talk to two different Salesforce orgs, they would have different custom fields on their standard objects, and different custom objects from each other.
2. Filters
Even though Filters are not the origin or destination of a record, they still potentially affect the shape of the record as it is processed by that Filter.
Examples:
The Relationships Filter that comes packaged with Valence adds the Master-Detail or Lookup field and its value to the record as it goes into Salesforce so that the relationship is populated.
A Constants Filter might create a new field on each record called
regionand set a certain value on it.
Filters can share information about their impact on the schema of a record by implementing the SchemaAwareTransformationFilter interface. Valence will incorporate these details into the Transformations screen so that admins can understand exactly what effect a particular Filter is having on records.
3. Link Splits
Link Splits connect two Links together, passing records from one to the other. This means that the schema from the first Link will spill over into the schema on the second Link. This concept can be a little mind-bending at first, so here’s a real-world example:
Let’s say you have an “Invoice” record arriving in Salesforce, and it holds information about the Invoice itself (total, date, paid/unpaid) and also contains several line items specifying exactly what was purchased. You want to create a record in Invoice__c, and also one record in InvoiceLineItem__c for each line item on the original record. How can you do this?
You set up a Link that takes an Invoice and writes to Invoice__c, and you set up a Link Split to a second Link that takes an InvoiceLineItem and writes to InvoiceLineItem__c. You of course need to get those line items out of the first record, but maybe you want to mark each line item as paid if the Invoice itself came in as paid. And also you want to populate a Master-Detail field on InvoiceLineItem__c relating it to the Invoice__c that was just created by the first Link.
This means you’ll want to know each of these schemata:
The source side of the Invoice (to know if it was paid)
The target side of the Invoice (to know its Salesforce ID that was just created)
What each line item looks like (so we can map line item fields into InvoiceLineItem__c)
The schema for InvoiceLineItem__c (so we can pick fields to write to)
Phew! That’s a lot! Luckily, we’ve got you covered. Valence will dynamically inspect the schema of both sides of the original Link, and bring them into the child Link under the prefixes $ParentSource and $ParentTarget respectively. Here’s what that looks like in the schema browser:

So now in your second Link (the one that writes to InvoiceLineItem__c), you can have a mapping from $ParentTarget.Id to the Master-Detail field InvoiceLineItem__c.ParentInvoice__c so that each line item stays connected to its newly-create Invoice__c record.
4. Field Custom Metadata Type
In addition to all the dynamic schema discovery, there is a special custom metadata type to represent fields that exist but for whatever reason aren’t discoverable. Maybe you are working with an API that doesn’t have any way to inspect its schema. You can load field definitions into this custom metadata type and Valence will make them part of what is shown to admins and available for mapping/transformation.
5. Sync Events
Finally, each Sync Event will keep track of the fields that actually exist on the records that it processed. The Sync Event will tell Valence things like population percentage, last seen date, and example values.
Typically the Sync Event is just enriching a field definition that was already provided to Valence by one of the other layers, but it also functions as a last line of defense. Even if none of the other layers mentioned a particular field, the Sync Event will catch it.
Bottom line: If a field exists on a record, you will know it’s there and as much detail about it as we can give you, and you will be able to work with it in your transformations.
Note
The layers mentioned above are in order of importance from top to bottom. A field will be attributed to the first layer that mentions it. This means that if the only layer that saw a field is the Sync Event, in the interface you will see that it was reported by a Sync Event. However, if both an Adapter and then a Sync Event tell Valence about a field, the Sync Event is just confirming a field we were already expecting so the Adapter is considered the reporter.
Lazy Loading
Some (most?) schemata are sprawling. You are rarely working with just one entity, but also all the entities connected to it. There are relationships you could traverse until you ended up back where you started.
In order to manage all this Valence supports lazy loading for schema data. Adapters that implement the LazyLoadSchemaAdapter interface can be interrogated about a schema one layer at a time. As a user you will be able to do this from the schema browser screen. In the action buttons if there is an Expand button this field is a relationship to another entity or has nested properties that will be loaded into the screen if you click that button.

Let’s say you were pulling Contact records out of Salesforce, but you also wanted to bring their parent Account’s Region__c field. In the schema browser you would see the Contact.Account field as a RELATIONSHIP with an expand button. If you click on it all the fields that are on Account will load onto the screen, allowing you to see and work with Account.Region__c. By using Account.Region__c as a source field for a mapping on this Contact Link, Valence will use a SOQL relationship query and fetch both the Contact’s fields and its parent Account’s Region__c value in a single query.